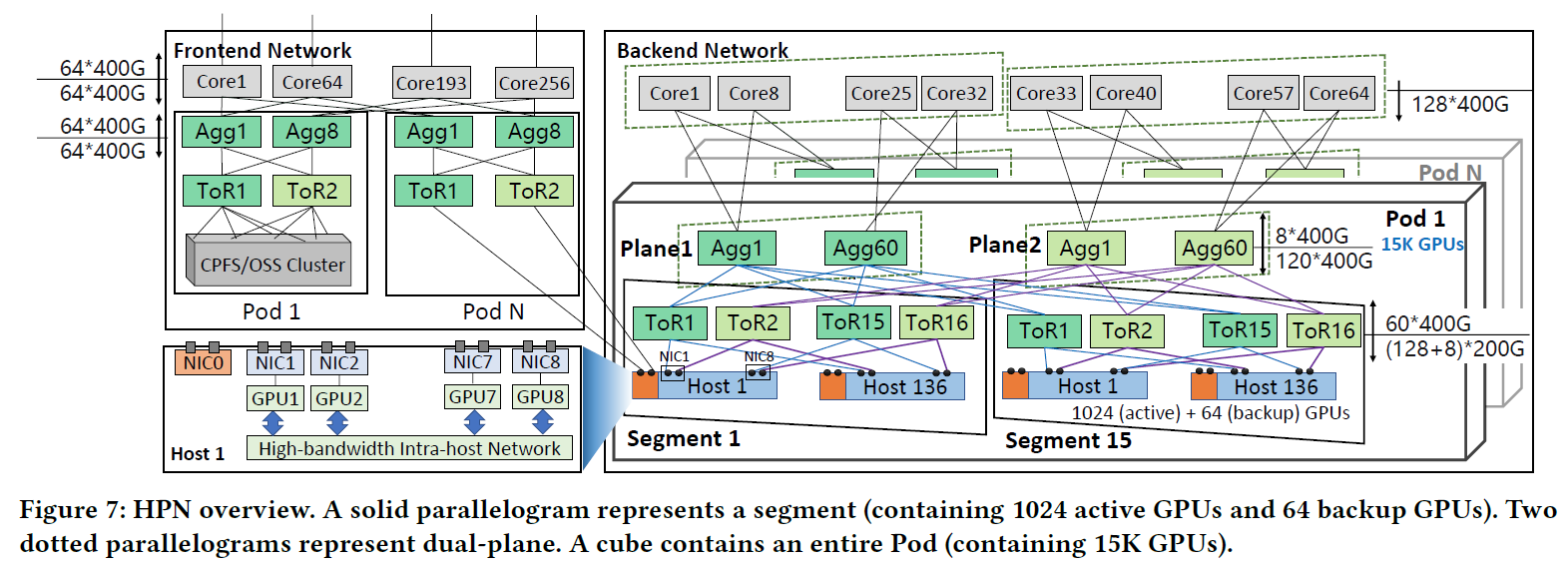
we survey the current state-of-the-art collective communication libraries (namely xCCL, including NCCL, oneCCL, RCCL, MSCCL, ACCL, and Gloo), with a focus on the industry-led ones for deep learning workloads.
常见的MPI库:MPICH、MVAPICH、OpenMPI
其他的非MPI库:OpenSHMEM(Open-source Symmetric Hierarchical MEMory)、UCX(Unified Communication X)、UCC(Unified Collective Communication)
常见的xCCL库:NVIDIA Collective Communications Library (NCCL)、AMD's ROCm Collective Communication Library (RCCL)、Gloo
1. 贡献与挑战
挑战
什么让同时代的xCCL比MPI更具有吸引力?
每种集合通信库的性能特性如何?
这些xCCL库是如何设计的?是否存在某种共享的设计模式?
贡献
总结和研究集合通信原语、网络拓扑、算法,为同时代的深度学习训练奠定基础
讨论这些研究的工业集合通信解决方案以及其细节测试
对比当前的集合通信库的性能情况
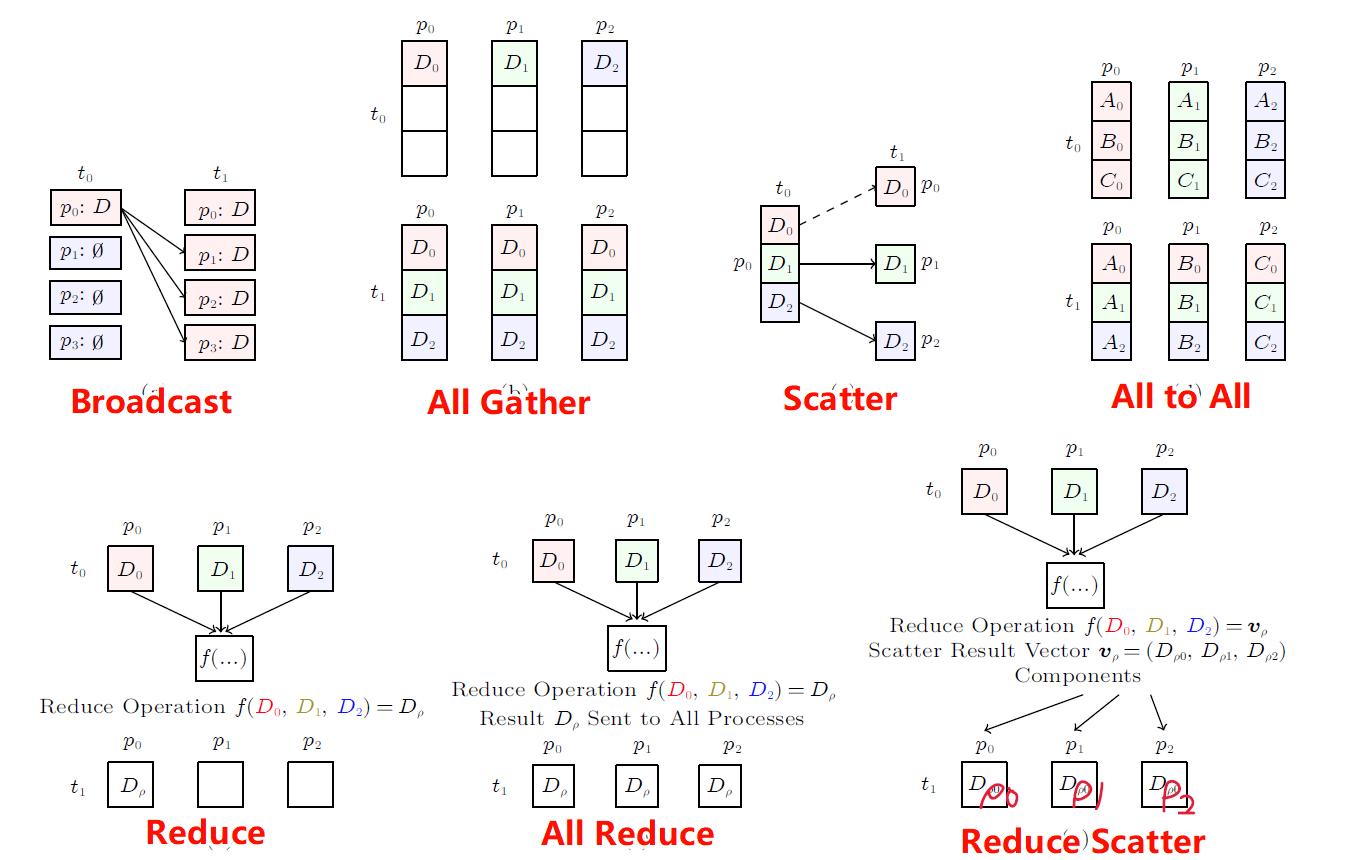
2. 集合通信原语
Broadcast:常用于将训练数据发送到各个设备上
All Reduce:广泛应用于分布式神经网络训练的后向传播阶段
All Gather、Scatter、All-to-All、Reduce、Reduce Scatter
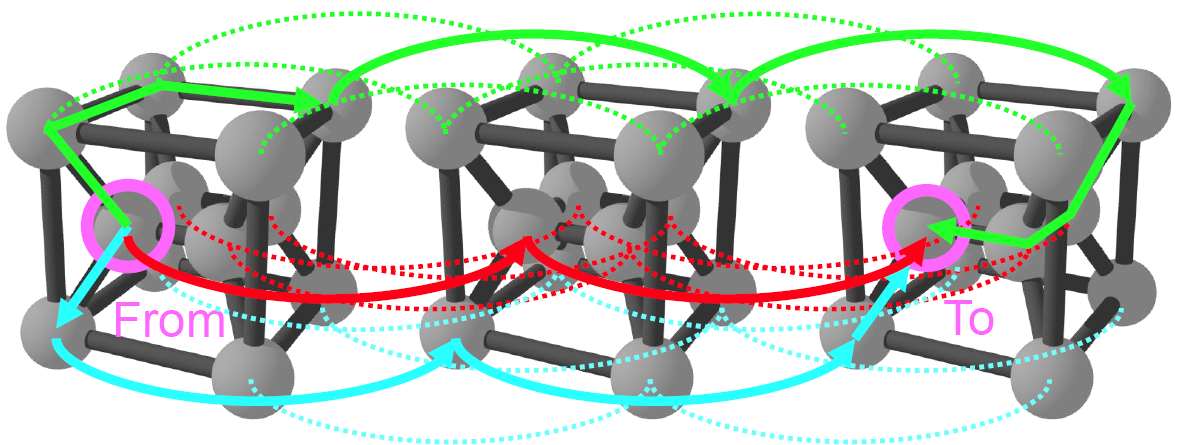
3. 网络拓扑架构
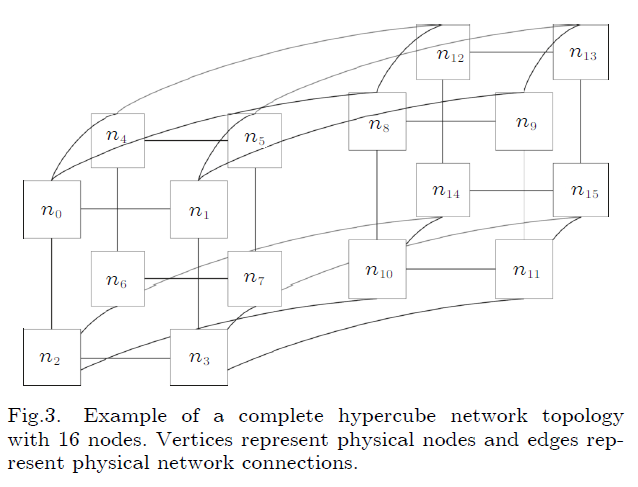
3.1 HyperCube
优点:高度的连接性,不容易发生故障
缺点:连接过于复杂,不适用于大规模集群系统,导致部署频率低
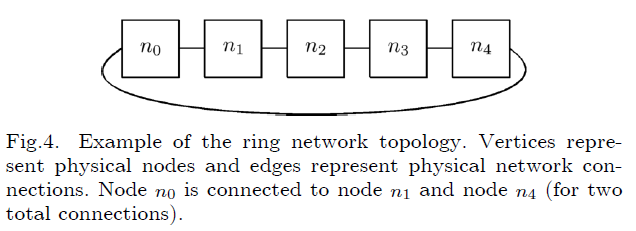
3.2 Ring
优点:无论是单向还是双向环,数据流只有一个流动方向,因此不会发生包碰撞;在一个现成的Ring拓扑中可以很容易添加一个节点;不需要中心服务器协调网络连接
缺点:在最坏的情况下,数据传输需要经过网络中的所有设备,导致数据传输不够灵活;网络中的任意一个节点故障都将会导致整个网络瘫痪;对于传输较小的数据包的情况下,通道的利用率较低,导致带宽碎片化
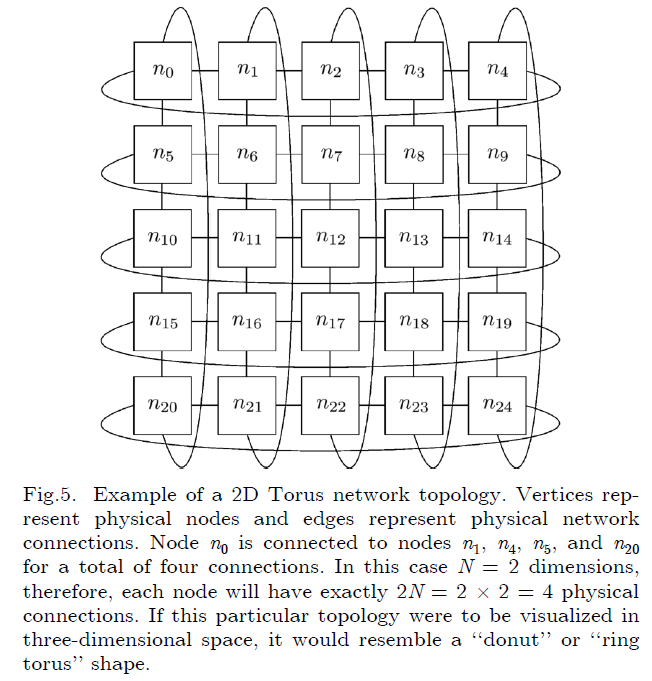
3.3 Torus
Torus拓扑是Ring拓扑的高纬度抽象
优点:可以明显的减小网络的直径;在网络中添加一个成员是比较容易的
缺点:随着维度的增加,网络布线的复杂度也在增加;在给定维度上添加新的节点将会带来更大的通信开销,消息的传递必须经过更多的节点
为了解决以上问题,有一个新的变种的Torus拓扑叫做folded-torus
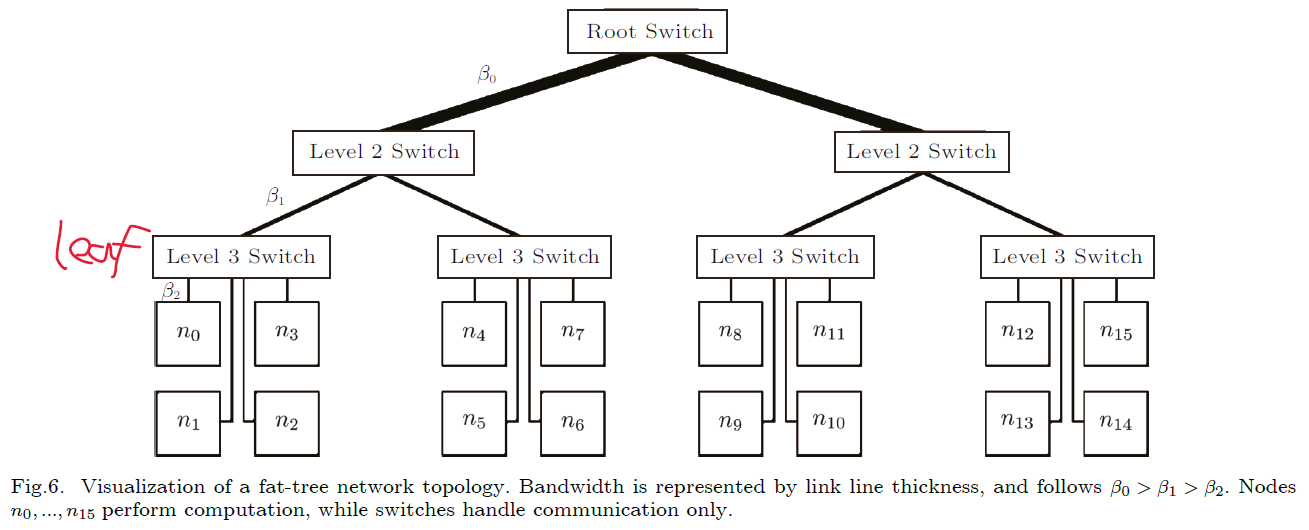
3.4 Fat-Tree
优点:节点之间的平均距离呈对数增长,因为他自身就是一个树状结构;具有递归可扩展性和可分区性,具有多种精心设计的路由算法;具有对称性、规律性、高度连接性
缺点:分支和根路由之间的带宽需求随着胖树的增长逐渐增加导致其实现成为瓶颈;由于胖树架构的特点,两个叶节点之间数据传输都必须经过叶路由
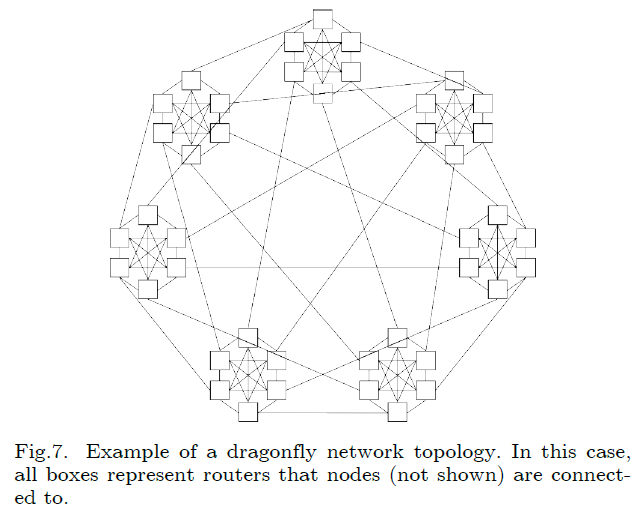
3.5 Dragonfly
优点:模块化的设计;节点内通信和节点间通信是解构的;具有很高的扩展性;在大规模集群上保持较少的跳数
缺点:构建成本较高;很高的路径多样性导致在一些流量模式下网络利用率和吞吐较低
为了解决以上问题,有一个新的变种的Dragonfly拓扑叫Dragonfly+
4. 集合通信算法
4.1 Ring
All Gather
每个进程发送自己的数据块到Ring数据流的下一个节点,并从Ring数据流的上一个节点接收数据块
每个进程发送自己上一步接收的数据,然后与上一步的操作相似
如果一个Ring中存在 p 个节点,则需要 p-1 步即可完成算法,如果数据量的大小为 n 则每一步收发的数据大小为 n/p 算法的总耗时为
T^{All \ Gather}_{Ring}=(p-1)\alpha +(\frac{p-1}{p})n\beta
All Reduce
All Reduce可以看作Reduce Scatter和All Gather的组合(Reduce Scatter可以使用Pairwise-Exchange算法实现)
\begin{align} T^{All \ Reduce}_{Ring}&=T^{Reduce \ Scatter}_{Pairwise \ Exchange}+T^{All \ Gather}_{Ring}\\ &=2(p-1) \alpha + 2n \beta + n\gamma-\frac{1}{p}(2n\beta+n\gamma) \end{align}
4.2 Binomial Tree
Broadcast
序号为 ({\rm root}+(p/2)) 的节点接收来自 \rm root 的数据
上一步接收数据的节点和 \rm root 节点座位新的 \rm root 节点重复上一步的动作
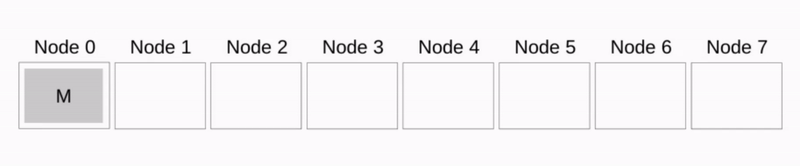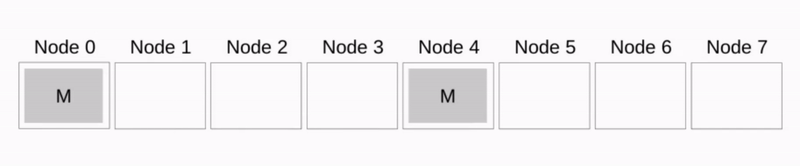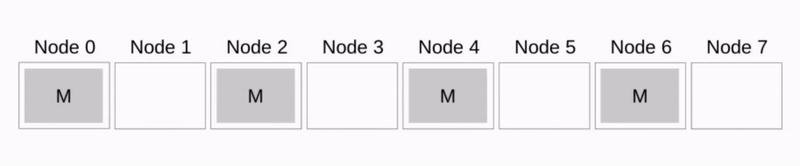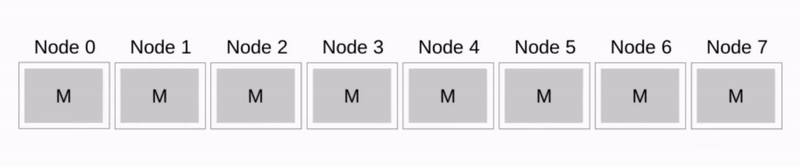
该算法按照递归的方式,总共需要进行 \lg p 步完成,假设每个节点每一步传输数据的大小为 n 则算法总耗时为:
T^{Broadcast}_{Tree}= (\lg p)(\alpha + n \beta)
因为算法耗时的对数延迟项,该算法在小数据包(小于12KB)或者节点数量小于8的条件下表现很好
Reduce
需要进行 \lg p 步完成算法,每步传输的数据量大小为 n 算法的耗时为:
T^{Reduce}_{Tree}=(\lg p)(\alpha+n\beta+n\gamma)
与Boradcast相似,在小数据包(小于等于2KB)条件下性能表现很好
4.3 Recursive Doubling
All Gather
每个节点与它的临近节点传输数据
每个节点和与它相距两个节点的节点传输数据
每个节点和与它相距四个节点的节点传输数据,并以此类推
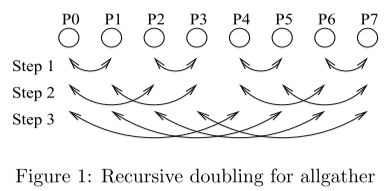
当节点的数量是2的次幂时,所有的数据传输将会在 \lg p 步完成,第一步每个节点交换的数据量为 n/p ,第二步每个节点交换的数据量为 2n/p ,以此类推,最后一个节点的数据交换量为 (2^{\lg(p-1)}n)/p 则算法的总耗时为
T^{All \ Gather}_{Rec-Dbl}=\lg p \alpha+(\frac{p-1}{p})n\beta
当节点的数据量是2的次幂时,该算法的性能表现很好,且适用于大多数的场景,但是当节点的数量不是2的次幂时该算法的性能表现较差
Reduce Scatter
算法过程和All Gather相似,在第一步,每个节点计算自己对应的数据块进行保留,不需要交换,因此每个节点传输的数据量为 n-(n/p) ,在第二步中,每个节点自身和上一步中通信的节点保留的数据块不进行交换,每个节点交换的数据量为 (n-(2n/p)) ,因此该算法的总耗时如下,该算法适用于极小的数据包(小于32B)
T^{Reduce \ Scatter}_{Rec-Dbl}=\lg p\alpha+(\lg p-\frac{p-1}{p})n\beta+(\lg p-\frac{p-1}{p})n\gamma
4.4 Recursive Halving
Reduce Scatter
每个节点与距离它为 p/2 的节点进行数据交换,每个节点与对应的节点交换自身数据的一半
每个节点与距离它为 p/4 的节点进行数据交换,每个节点与对应的节点交换的数据再次减半
以此按照递归操作
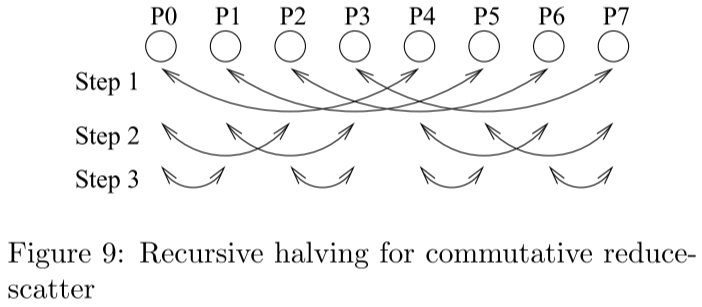
算法的总耗时为:
T^{Reduce \ Scatter}_{Rec-Half}=\lg p\alpha+(\frac{p-1}{p})n\beta+(\frac{p-1}{p})n\gamma
4.5 Pairwise Exchange
All Gather
Pairwise算法是Mesh算法的分步执行版本,通过合理的规划,将通信分解成多个步骤,每一步只从一个节点接收数据、向一个节点发送数据。比如对于 \rm rankid 为 i 的节点,第一步从 (i-1) 节点接收数据,向 (i+1) 节点发送数据;第二步从 (i-2) 节点接收数据,向 (i+2) 节点发送数据……以此类推。
总共需要 p-1 步,每步收发的数据大小为 n/p 则总的通信开销为
T^{All \ Gather}_{Pairewise}=(p-1)\alpha+(\frac{p-1}{p})n\beta
5. xCCL


5.1 NCCL
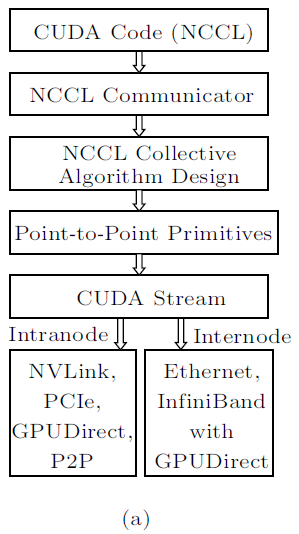
Ring
用于实现All-Reduce算法,将数据分成多个块,并且一个一个的在GPU之间进行传输,可以有效的降低GPU的空闲时间,但是当GPU设备的数量增多的时候,延迟将会增加
Double Binary Trees
由于Ring算法在GPU数量增加时会导致数据传输延迟的增加,在GPU数量较多时使用该算法可以解决该问题
5.2 MSCCL
Microsoft
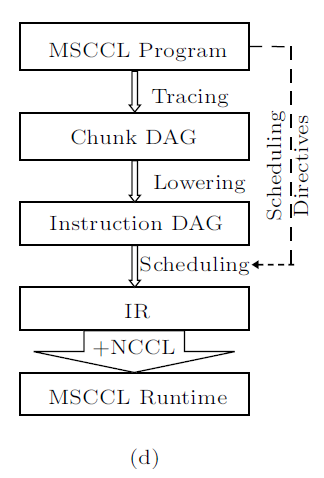
Ring
用于实现All-Reduce、Reduce-Scatter、All-Gather算法,MSCCL将多个通道分配到一个逻辑Ring中,通过这种方法,可以实现一对GPU之间不同的点对点通信。根据报文大小的不同,一条通道上的报文数量也不同。这种策略可实现逻辑环在各通道之间的分布,并有效地Overlap点对点操作。
All Pairs
GPU中通常有三种类型的缓冲区:输入缓冲区、输出缓冲区、临时缓冲区。由于Ring算法不适用于小数据包的场景,因此使用All Pairs算法实现All Reduce算法。All Pairs算法实现All Reduce只需要两步即可,因此在小数据包下的延迟非常低。
Hierarchical
为了实现All Reduce算法,可以使用分层网络,第一步在节点内进行Reduce Scatter,第二步在节点间进行Reduce Scatter,第三步在节点间进行All Gather,第四步在节点内实现All Gather
Two Step
主要用于All to All算法在节点间传输大量的小数据包
5.3 Gloo
Meta
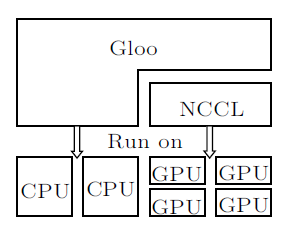
Ring
实现方法与标准的Ring相同
Ring-Chunked
在Ring算法的基础上将Buffer分割为多个Chunk以便于在进行本地Reduce操作时可以传输其他的Chunk
Halving Doubling
在All Reduce算法上Halving Doubling算法的设计与Recursive Halving和Doubling算法相似的,Halving Doubling算法使用两个节点的距离决定通信对。
在Reduce Scatter阶段使用Doubling算法,每个节点持有一份Reduce的结果;在All Gather阶段,使用Halving算法将每个节点中的Reduce结果收集在一起
Pairwise Exchange
Pairwise Exchange算法是简单的Halving Doubling算法,每一步上,节点被分成对,对与对之间通信的信息量相同。在 Gloo 中,Pairwise Exchange 用于基准测试
BCube
BCube算法将节点分割为多个组。首先,它在组内进程之间执行 Reduce-Scatter,在不同组的相应进程之间执行 All-Reduce。其次,每个组在组内执行 All-Gather,以便每个进程最终都能收到缩减结果。
5.4 ACCL
Hybrid
最大化带宽利用率,Hybrid算法将All Reduce算法解耦成一系列的微操作,并消除无意义的微操作。首先在组内使用Ring算法进行Reduce Scatter操作,然后再组间使用Halving Doubling算法进行All Reduce操作,最后在组内使用Ring算法进行All Gather操作
5.5 oneCCL
英特尔 oneAPI 集合通信库(oneCCL)是一个集合通信库,旨在开发一个单一的标准 API,兼容从 CPU、GPU 到 FPGA 等多种不同类型的硬件加速器,从而轻松加速深度学习训练工作负载。
5.6 RCCL
6. 集合通信与深度学习
6.1 Meta Workload
RMCs(recommendation model classes),Meta为了改善推理和训练的效率开发了一个软硬件结合的Neo智能体,它使用Pytorch作为后端实现的,可以实现高效、大规模的DLRM系统(Deep Learning Recommendation Model),它主要有三个关键技术
4D并行策略(table-wise parallelism, row-wise parallelism, column-wise parallelism, and data parallelism)主要目的是GPU的负载均衡,最小化开销
混合内核融合技术将参数更新和嵌入计算融合到同一个CUDA内核中。
一个新的硬件平台——ZionEX,适配4D并行策略的分布式训练平台
6.2 Google Workload
DistBelief:Dean J, Corrado G S, Monga R, Chen K, Devin M, Le Q V, Mao M Z, Ranzato M A, Senior A, Tucker P, Yang K, Ng A Y. Large scale distributed deep networks. In Proc. the 25th Int. Conf. Neural Information Processing Systems, Dec. 2012, pp.1223–1231.
6.3 Uber Workload
Michelangelo:Scaling machine learning at Uber with Michelangelo. https://www.uber.com/blog/scaling-michelangelo, Jan. 2023.
6.4 Amazon Workload
MiCS:Zhang Z, Zheng S, Wang Y S et al. MiCS: Near-linear scaling for training gigantic model on public cloud. Proceedings of the VLDB Endowment, 2022, 16(1): 37–50. DOI: 10.14778/3561261.3561265.
ZeRO:Rajbhandari S, Rasley J, Ruwase O, He Y X. ZeRO: Memory optimizations toward training trillion parameter models. In Proc. the 2020 SC, Nov. 2020.
7. 实验
7.1 实验条件
实验设备:4个SDSC Expanse cluster

测试负载:Meta’s PARAM、NCCL Test、OSU MPI Micro-Benchmarks
测试对象:NCCL、Gloo、MSCCL、CUDA-Aware MPI by MPICH、UCX
测试环境:Python 3.7、Pytorch 1.13、CUDA 11.6、NCCL 2.14.3、MSCCL 0.7.3、MPICH v4.0.2、UCX v1.13.1