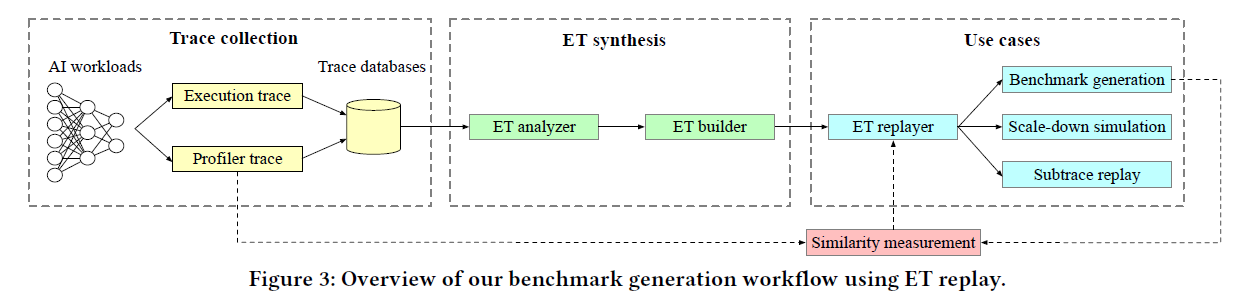
文献阅读《Mystique: Enabling accurate and scalable generation of production AI benchmarks》
1. 挑战与贡献 挑战 模型的多样性和更新速度无法与云基础设施上不断变化、高度多样化的人工智能生产工作负载相匹配 工程师或研究人员需要手动选择现有的生产或开源工作负载,并将其调整为可用于基准测试的形式
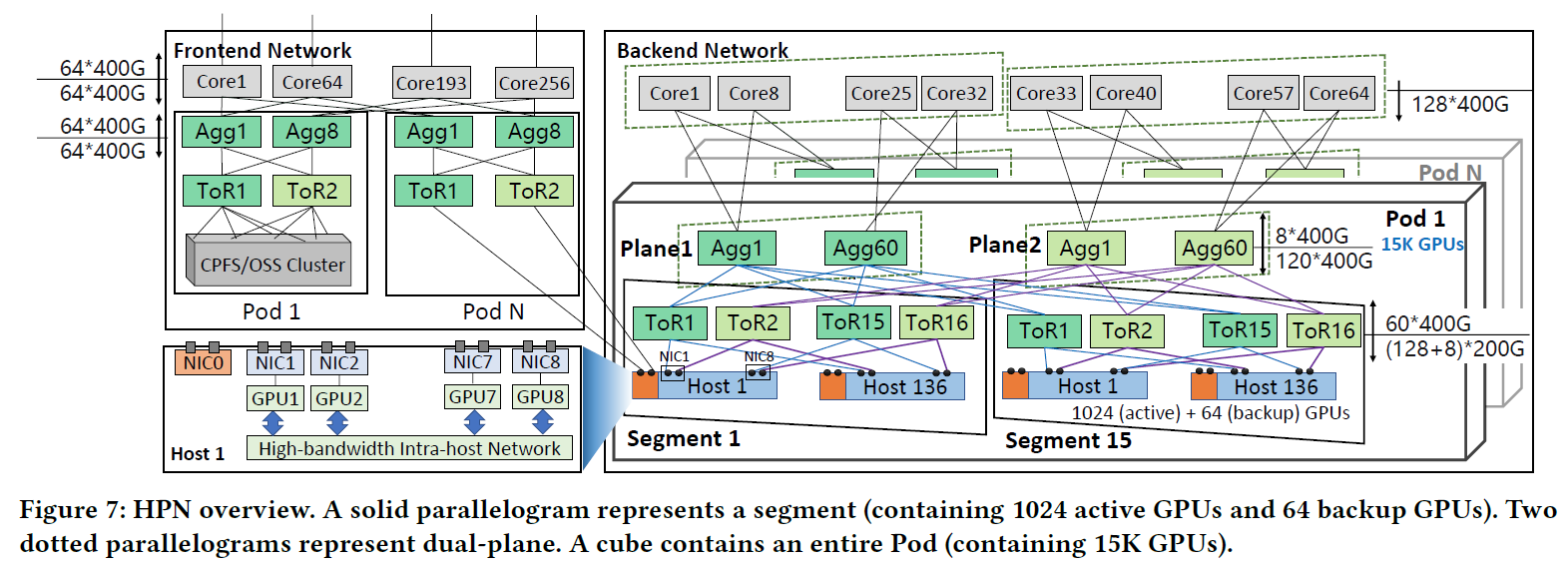
文献阅读《Alibaba HPN: A Data Center Network for Large Language Model Training》
Alibaba High Performance Network (HPN) HPN介绍了一种两层的双平面网络,可以在一个Pod中接入1.5w个GPU,通常需要3层Clos架构的网络才能容纳这么多GPU HPN 提出了一种新的双 ToR 设计,以取代传统数据中心网络中的单 ToR 1. 贡献与挑战
Llama2部署记录
1. 创建docker 1.1 docker命令 显示全部的镜像:docker images 创建一个容器:docker run ...<查看1.2节内容> 显示全部的容器:docker ps -a 启动一个容器:docker start &l
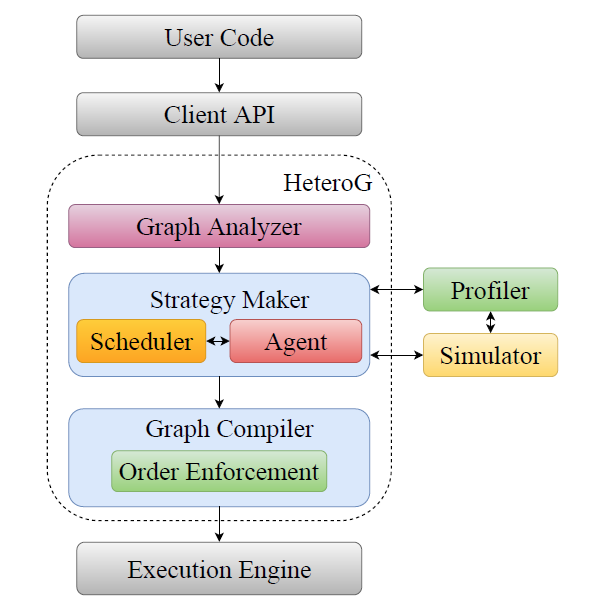
异构集群(Heterogeneous Clusters)
1. HeteroG 参考文献: Yi X, Zhang S, Luo Z, et al. Optimizing Distributed Training Deployment in Heterogeneous GPU Clusters: Proceedings of the 16th Intern
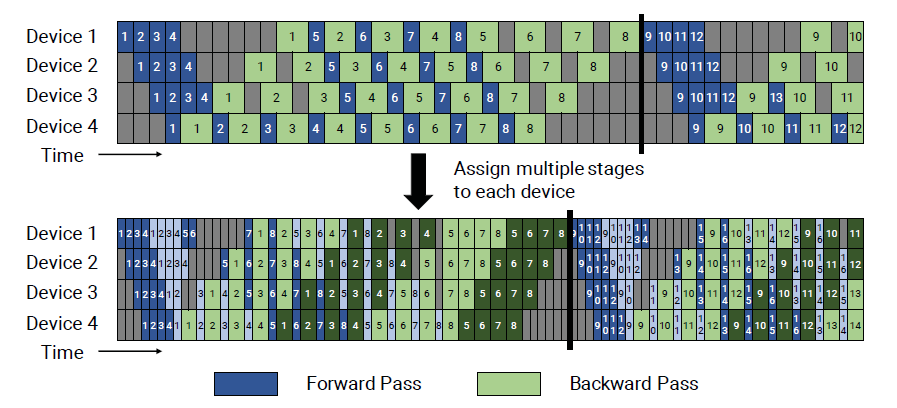
3D并行(3D Parallelism)
参考文献: Narayanan D, Shoeybi M, Casper J, et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM: SC' 21, November 14-19
最新文章
最新文章